




In database normalization, the Third Normal Form (3NF) is a property of a relation in a relational database. A relation is in 3NF if:
It is in Second Normal Form (2NF).
There are no transitive dependencies of non-prime attributes on the primary key.
In simpler terms, 3NF mandates that all the attributes in a table are functionally dependent only on the primary key.
Transitive dependency
Transitive Dependency is a concept in relational database normalization, especially significant when discussing Second (2NF) and Third Normal Form (3NF).
In the context of relational databases, a transitive dependency occurs when a non-prime attribute (an attribute that isn't a part of any candidate key) is functionally dependent on another non-prime attribute, rather than being dependent on the primary key (or any candidate key) directly.
An Example:
Consider a table that stores information about products:
Products
| ProductID | ProductName | Manufacturer | ManufacturerAddress |
| 1 | Laptop | Dell | Texas, USA |
| 2 | Mobile | Samsung | Seoul, South Korea |
| 3 | Keyboard | Dell | Texas, USA |
In this example:
ProductIDis the primary key.ProductName,Manufacturer, andManufacturerAddressare non-prime attributes.
You can observe the following functional dependencies:
ProductID -> ProductName(A product ID determines the product name)ProductID -> Manufacturer(A product ID determines its manufacturer)Manufacturer -> ManufacturerAddress(A manufacturer determines its address)
The third dependency indicates a transitive dependency. The attribute ManufacturerAddress is dependent on Manufacturer (another non-prime attribute) rather than on the primary key ProductID.
Why is Transitive Dependency a Problem?
Using the example above:
Redundancy: The address of Dell is repeated for every Dell product in the table. This could lead to the database being bloated with redundant data.
Update Anomaly: If Dell changes its address, you would have to update multiple rows. This can result in inconsistent data if some rows are updated and others aren't.
Insertion Anomaly: To insert a new manufacturer's address, you need to add a product for that manufacturer.
Deletion Anomaly: If you delete all products of a manufacturer, you inadvertently lose the manufacturer's address.
Solution:
To eliminate transitive dependencies and achieve Third Normal Form (3NF), you would decompose the table to remove these dependencies:
Products
| ProductID | ProductName | ManufacturerID |
| 1 | Laptop | 1 |
| 2 | Mobile | 2 |
| 3 | Keyboard | 1 |
Manufacturers
| ManufacturerID | Manufacturer | ManufacturerAddress |
| 1 | Dell | Texas, USA |
| 2 | Samsung | Seoul, South Korea |
By separating the data into two tables, you eliminate the transitive dependency and avoid the associated data anomalies.
Why it was invented:
Normalization, including 3NF, was introduced by E.F. Codd in his seminal paper "A Relational Model of Data for Large Shared Data Banks" in 1970. The motivation behind introducing normalization and its various forms, including 3NF, was:
To eliminate redundant data: By ensuring that data is stored in the right place, it reduces the redundancy.
To ensure data integrity: By minimizing redundancy, it reduces the chances of having inconsistent data.
To simplify the design: A well-normalized database structure makes it easier to modify and maintain.
What it solves in SQL:
Redundancy: Ensures that the same information is not duplicated in multiple places.
Update Anomalies: Helps in eliminating update issues. When data is duplicated, there's the possibility of updating some instances of that data and not others, leading to inconsistencies.
Insertion Anomalies: Eliminates problems that could occur when trying to insert data.
Deletion Anomalies: Eliminates issues where deleting data might unintentionally lead to other data getting lost.
Workshop
To understand and demonstrate 3NF, let's work with a fictional dataset.
Scenario: Suppose we have a college database with a table named StudentsCourses containing data about students, their courses, and instructors. The table looks like this:
StudentsCourses(StudentID, StudentName, CourseID, CourseName, InstructorName)
StudentIDis unique to each student.CourseIDis unique to each course.
However, the table has redundancy:
A student can be registered for multiple courses, so their name will appear multiple times.
A course can be taught by only one instructor but will appear multiple times for different students.
Data in the table:
| StudentID | StudentName | CourseID | CourseName | InstructorName |
| 1 | Alice | C101 | Math | Mr. Smith |
| 1 | Alice | C102 | Physics | Mr. Johnson |
| 2 | Bob | C101 | Math | Mr. Smith |
To normalize this to 3NF, we'll break it down into multiple tables to eliminate the redundant information.
1. Students Table:
Students(StudentID, StudentName)
| StudentID | StudentName |
| 1 | Alice |
| 2 | Bob |
2. Courses Table:
Courses(CourseID, CourseName, InstructorName)
| CourseID | CourseName | InstructorName |
| C101 | Math | Mr. Smith |
| C102 | Physics | Mr. Johnson |
3. StudentCourses Mapping Table:
StudentCourses(StudentID, CourseID)
| StudentID | CourseID |
| 1 | C101 |
| 1 | C102 |
| 2 | C101 |
Now, our data is in 3NF. The redundancy is removed, and the tables are related by keys. The StudentCourses table links the Students to their respective courses using a many-to-many relationship.
To test the normalization:
Insert data into the Students and Courses tables.
When registering a student for a course, you only need to insert the
StudentIDandCourseIDinto theStudentCoursestable.
Create database:
CREATE DATABASE CollegeDB;
GRANT ALL PRIVILEGES ON CollegeDB.* TO 'user'@'localhost';
FLUSH PRIVILEGES;
Here's the SQL to create and insert data:
CREATE TABLE Students(
StudentID INT PRIMARY KEY,
StudentName VARCHAR(255)
);
CREATE TABLE Courses(
CourseID VARCHAR(10) PRIMARY KEY,
CourseName VARCHAR(255),
InstructorName VARCHAR(255)
);
CREATE TABLE StudentCourses(
StudentID INT,
CourseID VARCHAR(10),
PRIMARY KEY(StudentID, CourseID),
FOREIGN KEY (StudentID) REFERENCES Students(StudentID),
FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);
INSERT INTO Students VALUES(1, 'Alice'), (2, 'Bob');
INSERT INTO Courses VALUES('C101', 'Math', 'Mr. Smith'), ('C102', 'Physics', 'Mr. Johnson');
INSERT INTO StudentCourses VALUES(1, 'C101'), (1, 'C102'), (2, 'C101');
With these tables, you can now query for information without redundancy and ensure the integrity of your data.
Here are some sample queries:
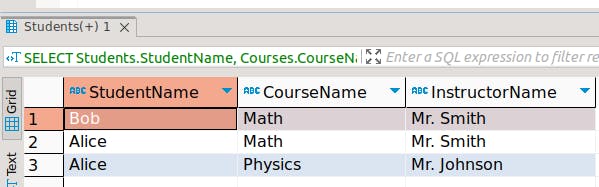
1. Retrieve all students and their courses:
SELECT Students.StudentName, Courses.CourseName, Courses.InstructorName
FROM Students
JOIN StudentCourses ON Students.StudentID = StudentCourses.StudentID
JOIN Courses ON StudentCourses.CourseID = Courses.CourseID;
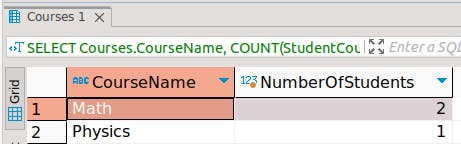
2. Get a list of courses along with the number of students enrolled:
SELECT Courses.CourseName, COUNT(StudentCourses.StudentID) AS NumberOfStudents
FROM Courses
LEFT JOIN StudentCourses ON Courses.CourseID = StudentCourses.CourseID
GROUP BY Courses.CourseName;
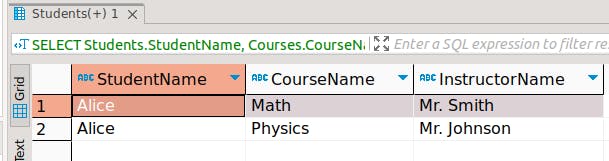
3. Find out which courses Alice is enrolled in:
SELECT Students.StudentName, Courses.CourseName, Courses.InstructorName
FROM Students
JOIN StudentCourses ON Students.StudentID = StudentCourses.StudentID
JOIN Courses ON StudentCourses.CourseID = Courses.CourseID
WHERE Students.StudentName = 'Alice';
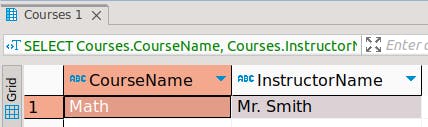
4. Retrieve all courses taught by a specific instructor:
SELECT Courses.CourseName, Courses.InstructorName
FROM Courses
WHERE Courses.InstructorName = 'Mr. Smith';
5. Delete a student record and their associated enrollments:
-- Be careful with DELETE statements!
-- This will delete Alice's record and her enrollments.
DELETE FROM Students WHERE StudentName = 'Alice';
DELETE FROM StudentCourses WHERE StudentID NOT IN (SELECT StudentID FROM Students);
These queries demonstrate how you can retrieve information without redundancy and maintain data integrity in your normalized database. Always use caution when performing DELETE operations, especially on production databases, as they permanently remove data.