





Table of contents
- What is a Kubernetes Liveness Probe?
- How Does It Work?
- Liveness Probe Parameters
- Use Cases of Liveness Probes
- Why Do We Need Liveness Probes?
- Liveness Probes Best Practices
- 1. Carefully Choose the Probe Type
- 2. Optimize Probe Parameters
- 3. Design a Meaningful Health Check Endpoint
- 4. Avoid Using Heavy Operations in Probes
- 5. Handle Probe Paths Securely
- 6. Use Liveness Probes in Conjunction with Readiness Probes
- 7. Monitor and Log Probe Activity
- 8. Regularly Review and Test Probe Configurations
- Workshop: Create Flask app with HTTP health endpoint and deploy liveness probe for it
- Step 1: Create the Flask Application
- Step 2: Create a Requirements File
- Step 3: Dockerize the Application
- Step 4: Build and Run the Docker Container
- Step 5: Deploy to Docker Hub
- Part 2: Deploy HTTP liveness probe in Kubernetes cluster
- Step 1: Ensure Your Docker Image is Accessible
- Step 2: Create a Kubernetes Deployment with a Liveness Probe
- Step 3: Expose Your Application
- Step 4: Access Your Application
- Step 5: Monitor the Liveness Probe
- References:
Kubernetes Liveness probes are a crucial part of managing containerized applications within a Kubernetes cluster. They help ensure that applications running in pods are healthy and functioning correctly. The kubelet (agent running on each node) executes these probes periodically to assess the application's health.
What is a Kubernetes Liveness Probe?
A Liveness probe is a mechanism in Kubernetes that allows you to check the health of a pod. Kubernetes uses this check to understand whether the application running in a pod is alive or dead. If the application is found to be not responding or in a non-functional state, Kubernetes can automatically restart the pod to try and restore its functionality to a healthy state.
For example, liveness probes could catch a deadlock, where an application is running, but unable to make progress. Restarting a container in such a state can help to make the application more available despite bugs.
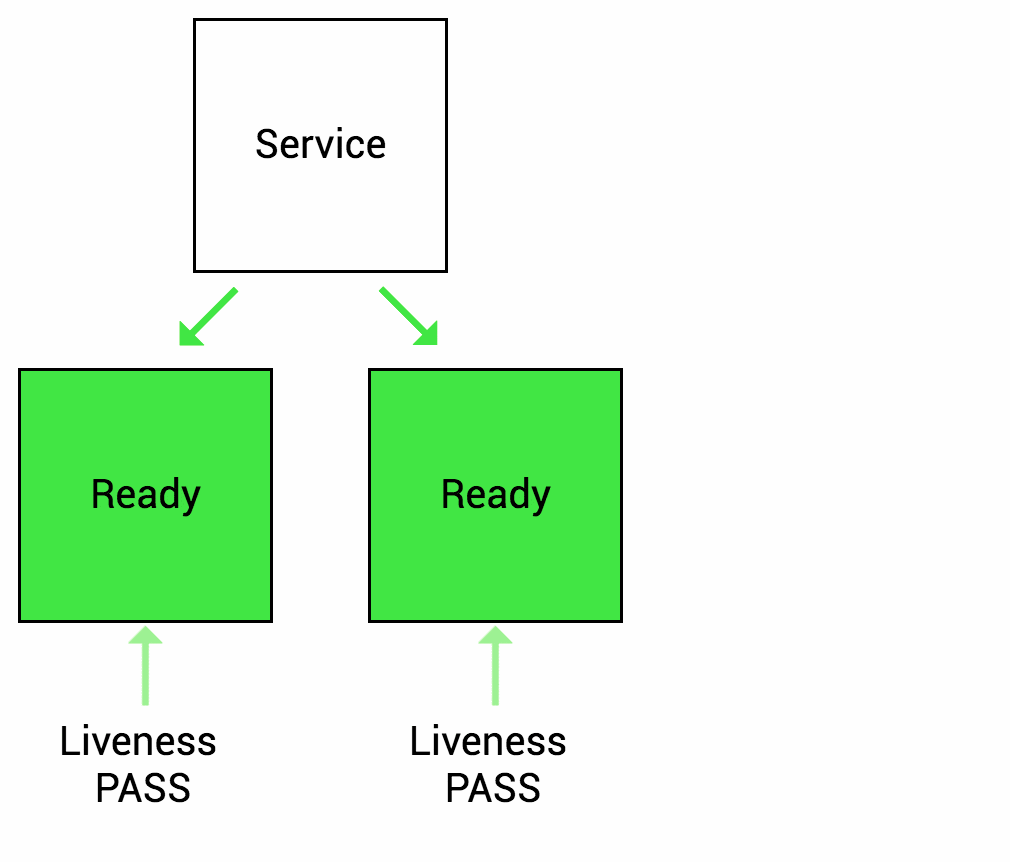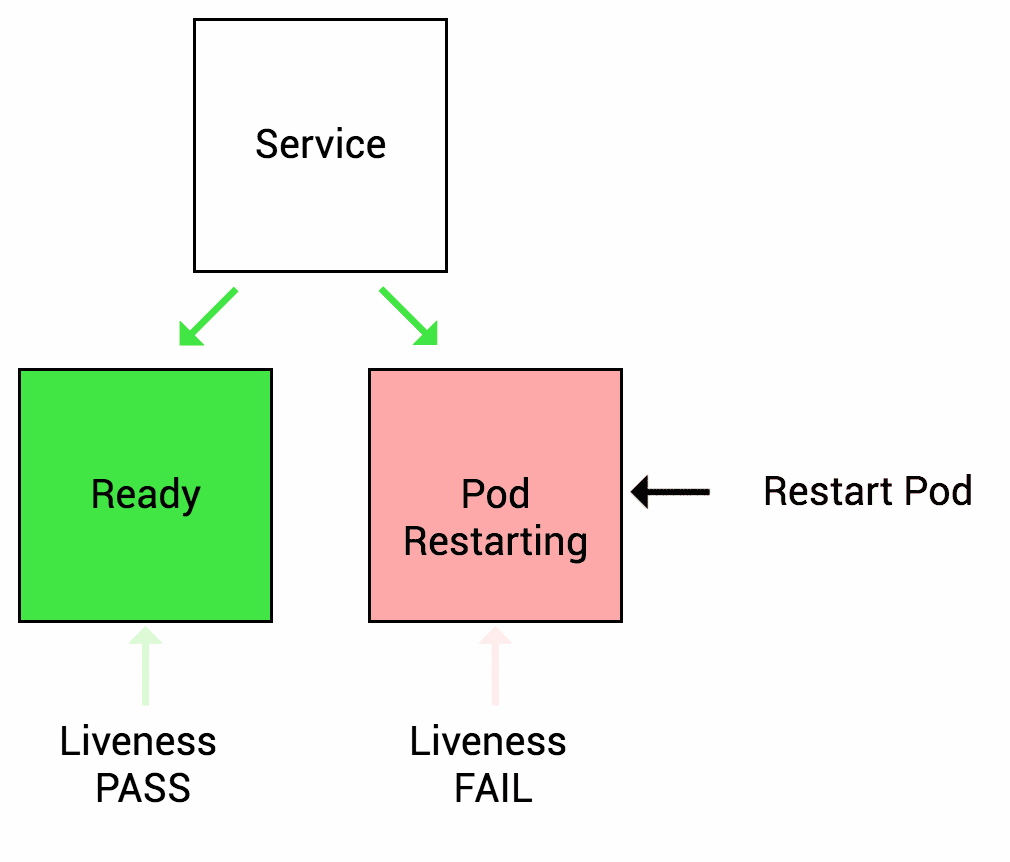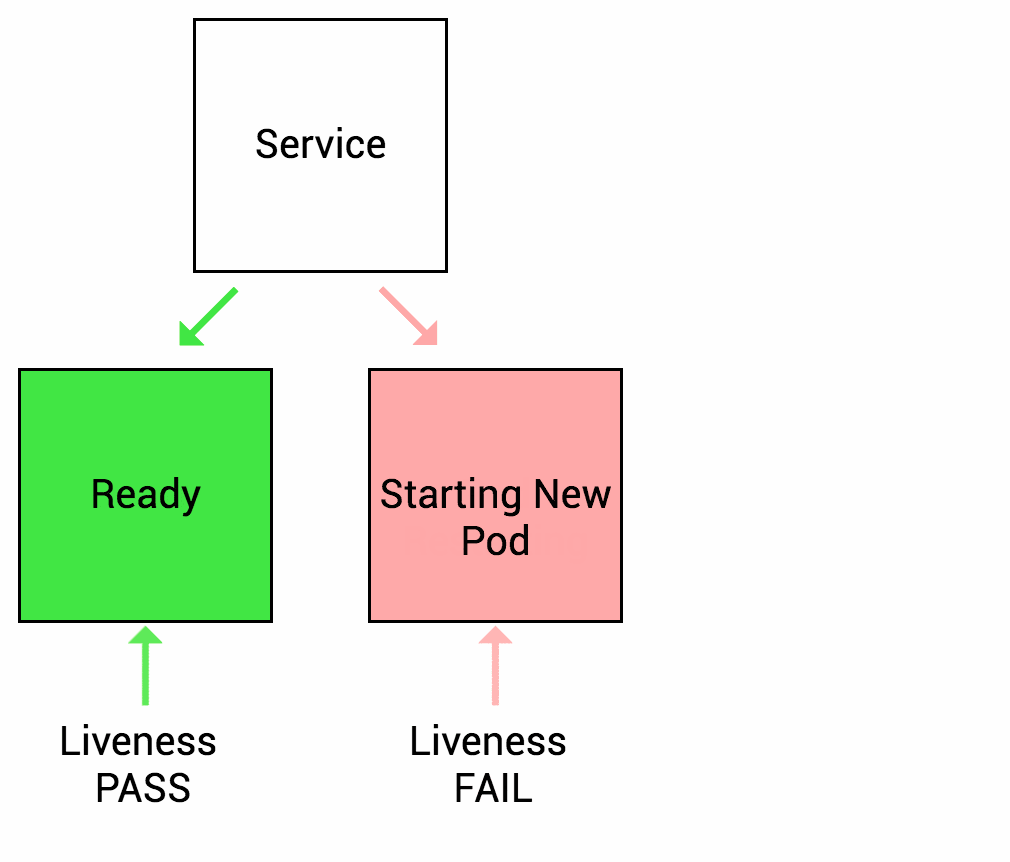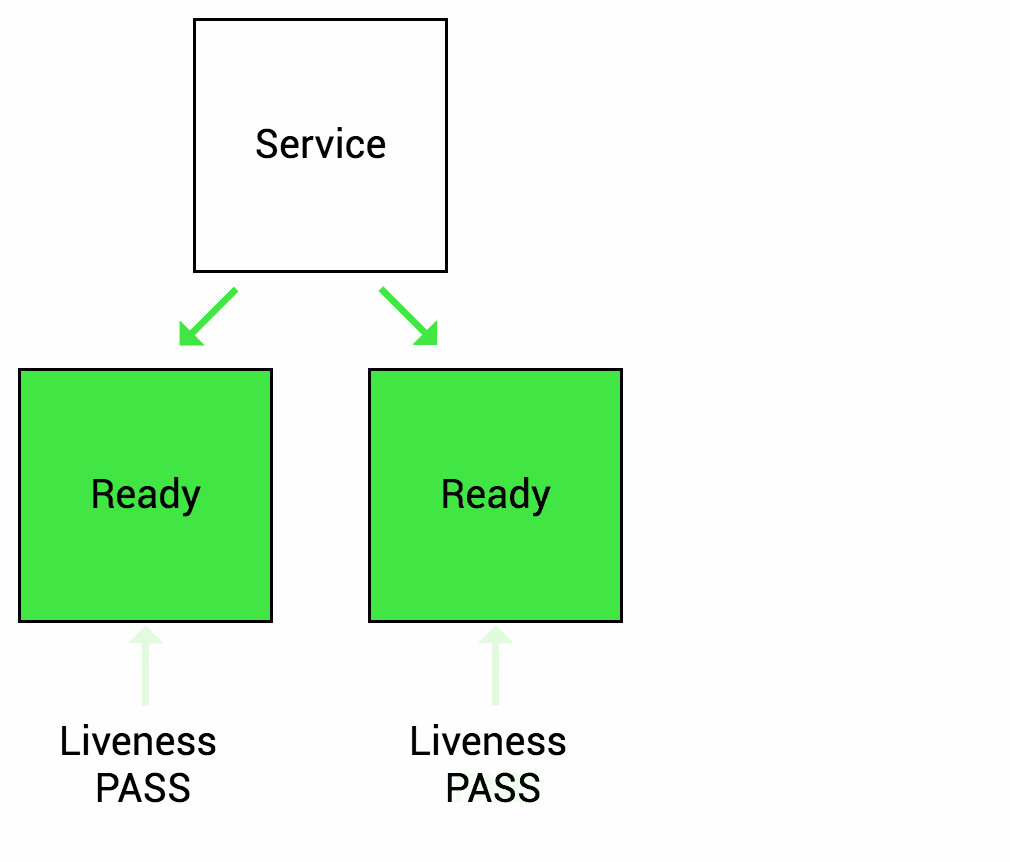
Image source: wideops.com
How Does It Work?
You can define Liveness probes in the pod's specification. Kubernetes supports several methods for performing health checks, including:
HTTP GET: Kubernetes sends an HTTP GET request to a specified path on the container's IP address. If the probe receives a response with a status code is 2xx or 3xx, it is considered successful.
TCP Socket: Kubernetes tries to establish a TCP connection to a specified port on the container. If the connection is established, the probe is considered successful.
Exec: Kubernetes executes a specified command inside the container. If the command exits with a status code of 0, the probe is considered successful.
gRPC handler: As of Kubernetes version v.1.24, and if your application implements gRPC Health Checking Protocol, kubelet can be configured to use it for application liveness checks. You must enable the
GRPCContainerProbefeature gate in order to configure checks that rely on gRPC.Action on Failure: When a liveness probe fails repeatedly (according to the configured
failureThreshold), thekubeletrestarts the container based on the pod'srestartPolicy.
Below are examples of how you might configure each type of Liveness probe in a Kubernetes pod specification. Each example is part of a pod's YAML definition, specifically within the spec.containers field for a given container:
HTTP GET Probe Example
apiVersion: v1
kind: Pod
metadata:
name: http-get-liveness
spec:
containers:
- name: liveness-http
image: your-image
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
timeoutSeconds: 2
periodSeconds: 5
failureThreshold: 3
This example configures a Liveness probe that performs an HTTP GET request to the /healthz endpoint on port 8080 of the container. Kubernetes considers the probe successful if the endpoint returns a status code in the 200-399 range.
TCP Socket Probe Example
apiVersion: v1
kind: Pod
metadata:
name: tcp-socket-liveness
spec:
containers:
- name: liveness-tcp
image: your-image
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
timeoutSeconds: 1
periodSeconds: 5
failureThreshold: 3
In this example, the Liveness probe attempts to establish a TCP connection to port 8080 on the container. If the probe can establish the connection, it is considered successful.
Exec Probe Example
apiVersion: v1
kind: Pod
metadata:
name: exec-liveness
spec:
containers:
- name: liveness-exec
image: your-image
livenessProbe:
exec:
command:
- sh
- -c
- test -e /tmp/healthy
initialDelaySeconds: 15
timeoutSeconds: 1
periodSeconds: 5
failureThreshold: 3
This example configures a Liveness probe that executes a command inside the container. The command checks for the existence of a file /tmp/healthy. If the command exits with a status code of 0 (indicating that the file exists), the probe is considered successful.
Liveness Probe Parameters
initialDelaySecondsspecifies how long to wait before the first probe is initiated. This allows your application to start up before Kubernetes begins health checks.timeoutSecondsis the number of seconds after which the probe times out.periodSecondsspecifies how often (in seconds) to perform the probe.failureThresholdis the number of times Kubernetes will try the probe before giving up and restarting the container.
Make sure to adjust the initialDelaySeconds, timeoutSeconds, periodSeconds, and failureThreshold values according to the specific requirements and behavior of your application to avoid premature or unnecessary restarts.
Use Cases of Liveness Probes
Self-Healing Applications: Automatically restart containers that are no longer responding to user requests or have entered an unhealthy state due to issues like memory leaks or deadlocks.
Service Availability: Ensure that services are continuously available and that any pods that become unresponsive are quickly identified and replaced.
Proactive Maintenance: Liveness probes can be used as part of a larger health check strategy, along with readiness probes and application-specific health checks, to proactively identify and address application issues before they impact users.
Why Do We Need Liveness Probes?
Automatic Recovery: They allow Kubernetes to automatically restart containers that have failed, crashed, or are no longer responsive. This is critical for maintaining the high availability of applications.
Improved Reliability: By removing or restarting unhealthy pods, Liveness probes help maintain the overall health of the system, leading to more reliable services.
Zero-Downtime Deployments: In conjunction with readiness probes and other Kubernetes features, they ensure that only healthy pods are serving traffic, which is vital for achieving zero-downtime deployments.
Liveness Probes Best Practices
Implementing Liveness probes in Kubernetes is a critical part of ensuring that your applications remain healthy and available. However, to get the most out of Liveness probes and avoid common pitfalls, it's important to follow best practices:
1. Carefully Choose the Probe Type
Select the most appropriate probe type (HTTP GET, TCP Socket, or Exec) based on the nature of your application and what accurately reflects its health. For example, use an HTTP GET probe for web servers where you can query a specific endpoint but consider a TCP Socket or Exec probe for applications that don't serve HTTP content.
2. Optimize Probe Parameters
Adjust the probe parameters (initialDelaySeconds, periodSeconds, timeoutSeconds, successThreshold, failureThreshold) based on the specific requirements and behavior of your application. Setting these parameters too aggressively might result in unnecessary restarts, while setting them too leniently could delay the recovery of a failing application.
initialDelaySeconds: Give your application enough time to start up before the first probe is executed. If your application has a lengthy initialization process, consider this in your delay timing.periodSecondsandtimeoutSeconds: Configure these values to avoid overwhelming your application with health checks, while still allowing timely detection of failures.failureThreshold: Set an appropriate threshold for failures that considers normal temporary fluctuations in application health.
3. Design a Meaningful Health Check Endpoint
For HTTP GET probes, ensure the endpoint you are checking (/healthz is a common convention) performs meaningful checks relevant to your application’s health. This could include checking database connections, external dependencies, or other critical internal states. However, be cautious not to make these checks too resource-intensive, as they will be run frequently.
4. Avoid Using Heavy Operations in Probes
The code executed by your probes should be lightweight and fast to execute. Heavy operations could impact the performance of your application and also skew the probe's ability to accurately reflect the application's health.
5. Handle Probe Paths Securely
If your health check endpoint is accessible via a public network, ensure that it does not expose sensitive information about the application's internal state. Consider security implications and possibly restrict access to the health check endpoint.
6. Use Liveness Probes in Conjunction with Readiness Probes
While Liveness probes help Kubernetes know when to restart a container, Readiness probes tell Kubernetes when a container is ready to start accepting traffic. Using them in tandem can ensure that traffic is only sent to healthy, ready containers, improving the overall reliability and availability of your services.
7. Monitor and Log Probe Activity
Keep an eye on the logs and metrics related to your Liveness probes. Unexpected restarts or probe failures can indicate issues with the probe configuration or underlying problems with the application. Monitoring these can provide insights into the health of your system and help with troubleshooting.
8. Regularly Review and Test Probe Configurations
Application behavior and dependencies can change over time, which may require adjustments to your Liveness probe configurations. Regularly review and test your configurations to ensure they remain effective and appropriate for your application’s needs.
By adhering to these best practices, you can effectively use Liveness probes to enhance the reliability and self-healing capabilities of your applications running in Kubernetes.
Workshop: Create Flask app with HTTP health endpoint and deploy liveness probe for it
In this workshop you'll go through creating a simple application with a /healthz HTTP endpoint that reports the application's health status. We'll use Python and Flask for the application, dockerize it and then deploy liveness probe for it in Kubernetes cluster.
Step 1: Create the Flask Application
First, create a new directory for your project and navigate into it.
Create a file named
app.pywith the following content:
from flask import Flask, jsonify
import random
import time
app = Flask(__name__)
# Initial status and timestamp
status_info = {
"status": "UP",
"last_update_time": time.time()
}
def update_status():
current_time = time.time()
# Update status every 30 seconds
if current_time - status_info["last_update_time"] >= 30:
# Randomly choose a new status
status_info["status"] = random.choice(["UP", "DOWN"])
status_info["last_update_time"] = current_time
@app.route('/healthz', methods=['GET'])
def healthz():
update_status() # Check if it's time to update the status
return jsonify({"status": status_info["status"]})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)
In this script, the update_status function checks if at least 30 seconds have passed since the last update. If so, it randomly updates the status to either "UP" or "DOWN" and resets the timestamp. The /healthz endpoint calls this function each time it's accessed, ensuring that the status can change over time but not more frequently than every 30 seconds.
This setup simulates a scenario where the health status of some component of your application (or the application itself) might vary over time, and you want to limit how often this status can change to avoid flapping or too frequent state changes.
This example provides a basic approach to simulating application health changes and can be expanded with more sophisticated logic to monitor actual application components or dependencies.
Step 2: Create a Requirements File
Create a file named requirements.txt in the same directory with the following content to specify the dependencies:
flask
Step 3: Dockerize the Application
- Create a
Dockerfilein the same directory with the following content:
# Use an official Python runtime as a base image
FROM python:3.9-slim
# Set the working directory in the container
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Make port 8080 available to the world outside this container
EXPOSE 8080
# Define environment variable
ENV NAME HealthStatusApp
# Run app.py when the container launches
CMD ["python", "app.py"]
This Dockerfile sets up a Python environment, installs the dependencies, and runs the application.
Step 4: Build and Run the Docker Container
With Docker installed and running on your machine, execute the following commands in your terminal:
# Build the Docker image
docker build -t healthz-app .
# Run the Flask app
docker run -p 8080:8080 healthz-app
Your Flask application is now running inside a Docker container and is accessible at http://localhost:8080/healthz.

Step 5: Deploy to Docker Hub
To deploy the image to Docker Hub, follow these steps:
- Log in to Docker Hub from your terminal:
docker login
- Tag your Docker image with your Docker Hub username and repository name:
docker tag healthz-app yourusername/healthz-app:latest
- Push the image to Docker Hub:
docker push yourusername/healthz-app:latest

Replace yourusername with your actual Docker Hub username. You'll need to create a repository on Docker Hub named healthz-app if it doesn't already exist.
You've created a simple health-checking application, dockerized it, and deployed it to Docker Hub.
Part 2: Deploy HTTP liveness probe in Kubernetes cluster
To deploy the Flask application with the /healthz endpoint to a Kubernetes cluster and set up a Liveness probe to monitor its health status, follow these steps. I'll assume you're using Minikube for a local Kubernetes environment.
Step 1: Ensure Your Docker Image is Accessible
Before proceeding, ensure the Docker image of your Flask application is either available in a public Docker registry Docker Hub. If you haven't pushed your Docker image to a registry, you can use the Minikube's Docker daemon to build your image directly:
- Start Minikube if it's not already running:
minikube start
- Set your terminal to use Minikube's Docker daemon:
eval $(minikube docker-env)
- Build your Docker image within the Minikube environment:
docker build -t health-status-app .
Step 2: Create a Kubernetes Deployment with a Liveness Probe
- Create a file named
flask-app-deployment.yamlwith the following content. Adjust theimagefield if you're using a different image name or a Docker registry:
apiVersion: apps/v1
kind: Deployment
metadata:
name: health-status-app
spec:
replicas: 1
selector:
matchLabels:
app: health-status-app
template:
metadata:
labels:
app: health-status-app
spec:
containers:
- name: health-status-app
image: health-status-app # Use your Docker image name. Prefix with registry if necessary.
ports:
- containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5 # Adjust based on your app's startup time
periodSeconds: 10
This YAML file defines a Kubernetes Deployment for your Flask application. The livenessProbe section configures Kubernetes to check the /healthz endpoint every 10 seconds, after an initial delay of 5 seconds.
- Deploy the application to your Minikube cluster:
kubectl apply -f flask-app-deployment.yaml

Step 3: Expose Your Application
To access your Flask application from outside the Minikube cluster, create a Service:
- Create a file named
flask-app-service.yamlwith the following content:
apiVersion: v1
kind: Service
metadata:
name: health-status-app
spec:
type: NodePort
selector:
app: health-status-app
ports:
- port: 8080
targetPort: 8080
nodePort: 30007
This YAML file creates a Service that exposes your Deployment on a specific port on the nodes of your cluster.
- Apply the Service configuration:
kubectl apply -f flask-app-service.yaml

Step 4: Access Your Application
Since you're using Minikube, you can access your application through the Minikube IP and the NodePort specified in your Service:
- Get the Minikube IP address:
minikube ip
- Access the application:
Open a browser and navigate to http://<minikube-ip>:30007/healthz, replacing <minikube-ip> with the IP address obtained from the previous command. You should see the health status of your application.

Step 5: Monitor the Liveness Probe
To check the status of your Liveness probe, you can use the kubectl describe command to inspect the state of the pods:
kubectl describe pod -l app=health-status-app
This command will provide detailed information about the pods running your application, including events related to the Liveness probe. If the probe fails, you'll see Kubernetes attempting to restart the pod based on the probe's failure.

These steps will deploy your Flask application to a Kubernetes cluster with a Liveness probe monitoring its health status through the /healthz endpoint, providing an example of how to ensure application reliability and self-healing within a Kubernetes environment.